
I acknowledge the Ngunnawal people, the traditional owners of these lands, and pay respect to all First Nations people present.
You might think that certain truths are so self‑evident that they transcend the need for evidence. For example, in the area of education, surely we know that:
- Parents are more likely to get their kids to school with the threat of losing income support.
- Literacy tests are a fair representation of students’ ability.
- Early childhood staff have the skills they need.
- A health program that is co‑designed with students and educators will address adolescents’ risk behaviours.
Alas, all these claims are wrong. Let me explain.
Do parents respond to financial incentives when it comes to getting their children to school? In 2016, researchers carried out a randomised trial in the Northern Territory of the ‘Improving School Enrolment and Attendance through Welfare Reform Measure’. Around 400 children were assigned to the treatment group, and the same number to the control group. Despite threats of payment suspension – and actual payment suspensions for some families – the program had zero effect on attendance (Goldstein and Hiscox 2018).
Are literacy tests fair? In Dubbo, a randomised trial across 1,135 students compared how students perform when tests are made culturally relevant – for example, by replacing a passage about lighthouses with a passage about the big dish in nearby Parkes. The improvement is sizeable, amounting to half the gap between Indigenous and non‑Indigenous students (Dobrescu et al. 2021).
Do early childhood staff have all the skills they need? A randomised trial of Leadership for Learning, a half‑year professional development program, suggests not. Randomising across 83 NSW centres, the study found that quality professional development boosted children’s achievement, especially in numeracy (Siraj et al. 2023). What is especially impressive about this study is that it shows the impact of professional development not just on educators, but on children.
And how about that school health program? Despite being co‑designed with students and educators, a randomised trial across 85 schools in Brisbane, Perth and Sydney found that the Health4Life program had no measurable impacts on alcohol use, tobacco smoking, recreational screen time, physical inactivity, poor diet or poor sleep (Champion et al. 2023).
What is distinctive about these studies is that they are not simply pilot programs or observational studies, but randomised trials, where participants are assigned to the treatment and control groups according to the toss of a coin. Randomisation ensures that before the experiment starts, the 2 groups are as similar as possible. This means that any difference we observe between them must be due to the intervention. In formal terms, randomisation provides an ideal counterfactual.
Without randomisation, what might go wrong? One danger is that the comparison group might be different from the outset. Students and schools who sign up for a new program could be quite different from those who say no. This is why medical researchers tend to trust randomised trials not only for assessing the impact of new drugs, but also increasingly for testing the impact of diet, exercise, surgery and more (for examples, see Leigh 2018).
Yet while the studies I’ve outlined above have produced valuable insights, they are the exception, not the rule. The typical educational research paper is an observational study with a sample size of around 30 pupils (Besekar et al. 2023). Randomised education policy trials remain rare.
This isn’t just true of educational policy. A study from the think tank CEDA examined a sample of 20 Australian Government programs conducted between 2015 and 2022 (Winzar et al. 2023). The programs had a total expenditure of over $200 billion. CEDA found that 95 per cent were not properly evaluated. CEDA’s analysis of analysis of state and territory government evaluations reported similar results. As the CEDA researchers note, ‘The problems with evaluation start from the outset of program and policy design’. Across the board, CEDA estimates that fewer than 1.5 per cent of government evaluations use a randomised design (Winzar et al. 2023, 44).
This finding echoes the Productivity Commission’s 2020 report into the evaluation of Indigenous programs, which concluded that ‘both the quality and usefulness of evaluations of policies and programs affecting Aboriginal and Torres Strait Islander people are lacking’, and that ‘Evaluation is often an afterthought rather than built into policy design’ (Productivity Commission 2020, 2).
Some impact evaluation tools are better than others. We recognise this in medicine, where randomised trials have demonstrated that treatments which were preferred by experts were actually worse for patients. In health, bad evaluation comes with a body count. Hydroxychloroquine for COVID cost over 16,000 lives (Pradelle et al. 2024). Antiarrhythmic drugs for errant heartbeats cost over 50,000 lives (Burch 2009, 269). Radical mastectomies for breast cancer disfigured 500,000 women while doing nothing to increase their odds of survival (Mukherjee 2010). Expert opinion and low‑quality before‑after studies supported these harmful treatments. If randomised trials had not put a stop to these treatments, the toll might have been greater still.
Process evaluations can be helpful if we are looking to iron out the practical implementation of a policy. But when it comes to impact evaluation, one way to think about the possible options for establishing ‘what works’ is through a ladder of evidence. This is the approach taken by the National Health and Medical Research Council and the Therapeutic Goods Administration when assessing new medical treatments (NHMRC 2009; TGA 2022). One such scale is the ‘Maryland Scale’ (Sherman et al. 1997) developed for evidence‑based policing, and widely used in other evaluation contexts today.
- Level 1: Correlation Studies
- Level 2: Before‑and‑After Studies Without Control Groups
- Level 3: Cohort Studies with Non‑Equivalent Groups
- Level 4: Controlled Studies with Pre‑ and Post‑Testing
- Level 5: Randomised Trials
The Maryland Scale isn’t the final word on evaluation quality. All else equal, studies should be given more weight if they have lower attrition rates and if they are conducted in Australia. A scoring guide for evaluations produced by one of the UK What Works Centres runs to 43 pages, discussing such fine points as the quality of instrumental variables, and the validity of regression discontinuity approaches (What Works Centre for Local Economic Growth 2016). A well‑conducted natural experiment may be more informative than a poorly‑run randomised trial.
The number of studies matters too. As we pointed out in the Global Commission on Evidence report (Global Commission 2022), researchers should always prefer systematic reviews over single studies.
But I’m sure it hasn’t escaped your notice that government is doing far more low‑quality evaluations than high‑quality evaluations. As the CEDA report shows, government evaluation has fallen short. For every well‑designed randomised policy trial (Level 5), governments have conducted dozens of observational pilot studies (Level 1). If you printed out all the pilot studies, you would destroy forests. If you printed out all the randomised trials, a few trees would do the job.
That’s where the Australian Centre for Evaluation comes in. Established a year ago, the centre aims to expand the quality and quantity of evaluation across the public service. Led by Eleanor Williams, armed with a modest budget and just over a dozen staff, the centre operates on smarts and gentle persuasion, not mandates or orders.
No agency is forced to use the services of the Australian Centre for Evaluation, but all are encouraged to do so. This reflects the reality that evaluation, unlike audit, isn’t something that can be done as an afterthought. A high‑quality impact evaluation needs to be built into the design of a program from the outset. For practical advice on running a great evaluation, check out the resources available on the Australian Centre of Evaluation site.
One way in which the centre operates is to strike partnerships with departments, which facilitate ongoing collaboration. Such an agreement has already been forged with the Department of Employment and Workplace Relations, and others are being discussed. The centre has also taken an active role in considering aspects that are relevant to all evaluations, such as rigorous ethical review and access to administrative microdata. Under David Gruen’s leadership, the Australian Bureau of Statistics has played a pivotal role in brokering access to administrative data for policy experiments.
Collaboration with evaluation researchers outside of government is critical too. Indeed, a recent ANZSOG event was titled ‘Academics are from Venus, public managers are from Mars’. Like ANZSOG, I am keen to change this impression and so I’m delighted to announce the establishment of a new Impact Evaluation Practitioners Network to bring government and external impact evaluators together. This is a joint initiative of the Australian Centre for Evaluation and the Australian Education Research Organisation, and I understand that many others have already expressed interest in joining and supporting the Network. I encourage all of you to join – you can find more details on how to register on the Australian Centre for Evaluation’s website.
Today, I am pleased to also announce that the Paul Ramsay Foundation is launching its Experimental Methods for Social Impact Open Grant Round. This will support up to 7 experimental evaluations conducted by non‑profits with a social impact mission. Grants last for 3 years and are up to $300,000 each. The Paul Ramsay Foundation gives a few examples, including programs aimed at improving education outcomes for young people with disabilities, reducing domestic and family violence, or helping jobless people find work. The Australian Centre for Evaluation will support this open grant round, and in particular will help to connect grantees with administrative data relevant to the evaluation. This announcement demonstrates the commitment to rigorous evaluation by Australia’s largest philanthropic foundation. I commend Paul Ramsay Foundation CEO Kristy Muir and her board for their leadership, and I hope that it inspires other foundations to also fund randomised trials of innovative programs. More information about the grant round can be found on the Paul Ramsay Foundation website.
Through the Australian Centre for Evaluation, we are keen to bust the myth that high‑quality evaluation is expensive, complicated and time consuming. Some randomised trials can be pricey and continue for decades. But the 4 studies I cited at the start of my speech were cheap and cheerful, taking less than a year, and costing thousands of dollars, not millions. Access to administrative data has been crucial in this effort, since data linkage is considerably cheaper than running surveys. We are also debunking the misconception that randomised trials are unethical. If government lacks good evidence that a program works, then how can it be unethical to have an experimental control group?
And good evaluation need not be hard. Plenty of resources are available to help run a good evaluation. The UK government’s Magenta Book provides a straightforward flowchart for selecting the right method for an evaluation, outlining when it might be appropriate to carry out a matching study, a synthetic control evaluation, or a stepped wedge randomised trial, in which the intervention is rolled out on a random basis, so that everyone eventually gets the treatment (HM Treasury 2020).
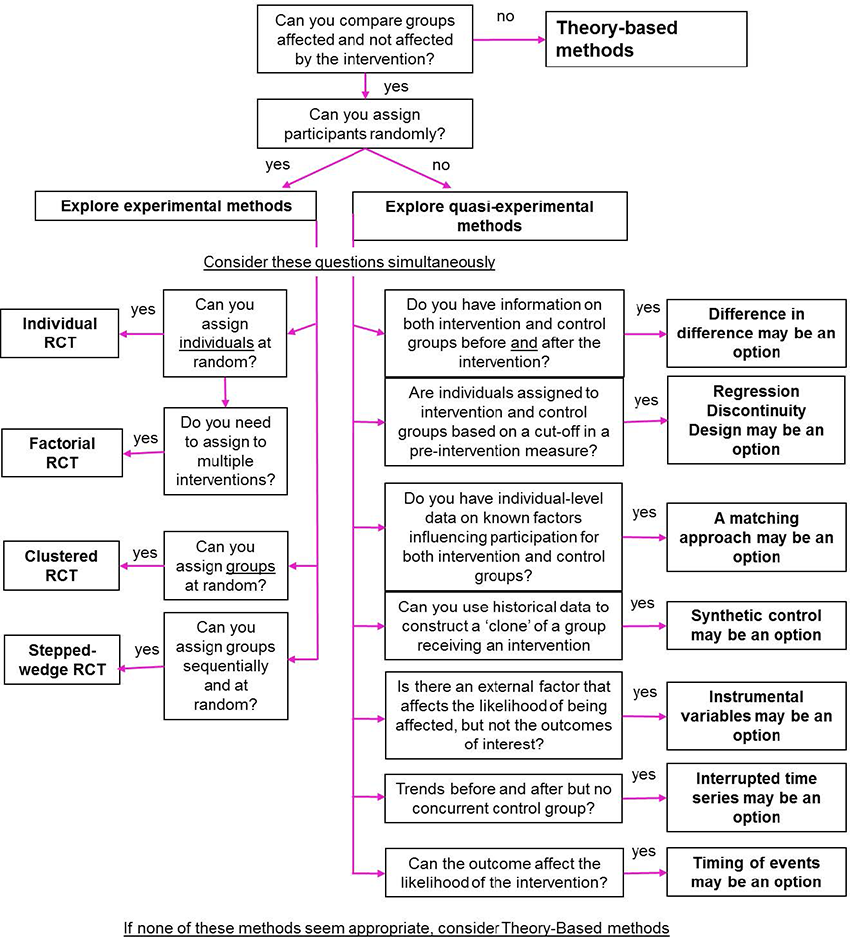
Source: Magenta Book
When we ask the question ‘what works?’, we are also asking ‘who does it work for?’. Some programs will invariably be more effective for women, First Nations people, those in regional areas, or people with more motivation. Where sample size permits, rigorous evaluation makes it possible to test for differential program impacts, which may lead governments to tailor programs to suit particular people.
Across Australia, the momentum towards more rigorous evaluation is growing. The BETA centre, within the Department of Prime Minister and Cabinet, has a track record of conducting randomised evaluations, producing innovative findings on how to increase workplace giving and reduce the overprescribing of antibiotics. Researcher Julian Elliott – who will be speaking later this afternoon – has pioneered living systematic reviews, which are updated regularly with the best evidence (Elliott et al. 2014). Last year, he founded the Alliance for Living Evidence (known as Alive).
Globally, we can learn from the British What Works Centres, a network of 12 centres that produce and distil evidence about what works in areas such as homelessness, crime reduction and local economic growth. A prominent What Works Centre is the Education Endowment Foundation, which has conducted over 100 randomised trials. It reports results in a dashboard format, showing for each study the cost and evidence strength (each on a 5‑point scale) and the impact (in months of learning).
In the United States, the Arnold Foundation has to date given away over US$2 billion, much of which has gone to support randomised trials across all areas of social policy. The Arnold Foundation doesn’t just produce evidence, it also works with US states to co‑fund the implementation of policies that are backed by the best evidence.
The US is also home to the Campbell Collaboration, which since 2000 has been producing systematic reviews on programs to reduce loneliness, counter violent extremism, tackle youth offending, prevent child neglect and much more. Like the Cochrane Collaboration’s systematic reviews of medical interventions, the Campbell Collaboration helps distil evidence for busy policymakers.
In Canada, the McMaster Health Forum operates as the secretariat for the Global Evidence Commission, whose 2022 report, led by John Lavis, drew together expertise from around the world to produce a set of recommendations on evidence use for citizens, governments and international organisations (Global Commission 2022).
What does the future hold? Just as evidence has increasingly been institutionalised into the training of medical professionals, it is likely that evaluation will become part of the standard toolkit for all Australian public servants. I like to imagine that as public servants apply for promotion to the Senior Executive Service, they will be asked not only ‘tell me about a management challenge you addressed’, but also ‘tell me about the best evaluation you ran’.
As new policy proposals come forward to Cabinet and the Expenditure Review Committee, it will be increasingly normal for proponents to draw on systematic evidence reviews, and explain how the program will be rigorously evaluated, adding to the evidence base. Where programs are to be tested, we will run experiments, not pilots.
Globally, it may be helpful for countries to join forces in producing systematic reviews and identifying evidence gaps. One proposal, currently being shaped by David Halpern and Deelan Maru, proposes that a handful of like-minded governments join forces to produce better systematic reviews and avoid duplication (Halpern and Maru 2024). I understand that Alex Gyani from the Behavioural Insights Team will share details of this report when he speaks later this afternoon. Like the Cochrane Collaboration and the Campbell Collaboration, such an approach can help expand our knowledge of what works, and put a spotlight on the areas where more evidence is needed.
A ‘what works?’ approach to government promotes democratic accountability (Tanasoca and Leigh 2024). It makes government more effective and efficient – producing better public services for every dollar we raise in taxes. But it especially matters for the most vulnerable. When government doesn’t work, the richest can turn to private options. But the poorest have nowhere else to turn, since they rely on well‑functioning government services for healthcare, education, public safety and social services. Getting impact evaluation right can deliver not just a more productive government, but a more egalitarian society.
References
Besekar S, Jogdand S and Naqvi W (2023) ‘Sample size in educational research: A rapid synthesis’, Working paper.
Burch D (2009) Taking the Medicine: A Short History of Medicine’s Beautiful Idea and Our Difficulty Swallowing it, Random House, New York.
Champion KE, Newton NC, Gardner LA, Chapman C, Thornton L, Slade T, Sunderland M, Hides L, McBride N, O’Dean S and Kay‑Lambkin F (2023) ‘Health4Life eHealth intervention to modify multiple lifestyle risk behaviours among adolescent students in Australia: a cluster‑randomised controlled trial’, The Lancet Digital Health, 5(5):e276‑e287.
Dobrescu I, Holden R, Motta A, Piccoli A, Roberts P and Walker S (2021) ‘Cultural Context in Standardized Tests’, Working paper, University of NSW, Sydney.
Global Commission on Evidence to Address Societal Challenges (2022) The Evidence Commission report: A wake‑up call and path forward for decisionmakers, evidence intermediaries, and impact‑oriented evidence producers, McMaster Health Forum, Hamilton.
Elliott JH, Turner T, Clavisi O, Thomas J, Higgins JP, Mavergames C and Gruen RL (2014) ‘Living systematic reviews: an emerging opportunity to narrow the evidence‑practice gap’, PLoS medicine, 11(2):e1001603.
Goldstein R and Hiscox M (2018) ‘School Enrolment and Attendance Measure Randomized Controlled Trial: Full Report’, Working Paper, Harvard University, Cambridge, MA.
Halpern D and Maru D (2024) A Blueprint for Better International Collaboration on Evidence, Behavioural Insights Team, nesta and ESRC, London.
HM Treasury (2020) Magenta Book: Central government guidance on evaluation, HM Treasury, London.
Leigh A (2018) Randomistas: How Radical Researchers Changed Our World, Black Inc, Melbourne.
Mukherjee S (2010) The Emperor of All Maladies: A Biography of Cancer, Simon and Schuster, New York.
National Health and Medical Research Council (2009) NHMRC levels of evidence and grades for recommendations for developers of guidelines, NHMRC, Canberra.
Pradelle A, Mainbourg S, Provencher S, Massy E, Grenet G and Jean‑Christophe LEGA (2024) ‘Deaths induced by compassionate use of hydroxychloroquine during the first COVID‑19 wave: an estimate’, Biomedicine & Pharmacotherapy, 171: article 116055.
Productivity Commission (2020) Indigenous Evaluation Strategy: Background Paper, Productivity Commission, Canberra.
Sherman L, Gottfredson D, MacKenzie D, Eck J, Reuter P and Bushway S, (1997) Preventing Crime: What Works, What Doesn’t, What’s Promising, NCJ 165366, National Institute for Justice, Washington DC.
Siraj I, Melhuish E, Howard SJ, Neilsen‑Hewett C, Kingston D, De Rosnay M, Huang R, Gardiner J and Luu B (2023) ‘Improving quality of teaching and child development: A randomised controlled trial of the leadership for learning intervention in preschools’, Frontiers in Psychology, 13: article 1092284.
Tanasoca A and Leigh A (2024) ‘The democratic virtues of randomized trials’, Moral Philosophy and Politics, 11(1):113–140.
Therapeutic Goods Administration (2022) Listed medicines evidence guidelines: How to demonstrate the efficacy of listed medicines is acceptable, Version 4.0, Therapeutic Goods Administration, Canberra.
What Works Centre for Local Economic Growth (2016) Guide to scoring evidence using the Maryland Scientific Methods Scale, What Works Centre for Local Economic Growth, London.
Winzar C, Tofts‑Len S and Corpuz E (2023) Disrupting Disadvantage 3: Finding What Works, CEDA, Melbourne.
Text descriptions
Text description of Figure 1
The chart titled "Figure 3.1. Selecting experimental and quasi-experimental methods" is a decision tree designed to help choose between different research methods based on specific criteria.
Here is a detailed description:
- **Theory-based methods**:
- The topmost box asks, "Can you compare groups affected and not affected by the intervention?" If the answer is "yes," it directs to the next question, "Can you assign participants randomly?" If "no," it suggests exploring quasi-experimental methods.
- **Exploring experimental methods**:
- This section begins with the question: "Can you assign participants randomly?" If "yes," the chart suggests:
- **Individual RCT (Randomized Controlled Trial)**: If you can assign individuals at random.
- **Factorial RCT**: If you need to assign multiple interventions.
- **Clustered RCT**: If you can assign groups at random.
- **Stepped-wedge RCT**: If you can assign groups sequentially and at random.
- This section begins with the question: "Can you assign participants randomly?" If "yes," the chart suggests:
- **Exploring quasi-experimental methods**:
- If you cannot assign participants randomly, it directs to considering several questions simultaneously:
- **Difference in Difference**: If you have information on both intervention and control groups before and after the intervention.
- **Regression Discontinuity Design**: If intervention assignment depends on a cut-off in a pre-intervention measure.
- **A matching approach**: If you lack information on factors influencing participation but have control for observed differences between groups.
- **Synthetic control variables**: If you can construct a "clone" of a group from historical data.
- **Instrumental variables**: If there is an external factor that affects the likelihood of being affected by the intervention.
- **Interrupted time series**: If you have data on trends before and after but no concurrent control group.
- **Timing of events**: If the outcome can affect the likelihood of the intervention.
- If you cannot assign participants randomly, it directs to considering several questions simultaneously:
The chart guides the user through a series of questions, leading to the selection of an appropriate experimental or quasi-experimental method based on the specifics of their research situation.
* Thanks to George Argyrous, Jon Baron, Jeff Borland, Sally Brinkman, Julian Elliott, Harry Greenwell, David Halpern, Frances Kitt and Cassandra Winzar for valuable comments on earlier drafts. All remaining errors and omissions are my responsibility.